페치 조인(fetch join)이란 JPQL에서 성능 최적화를 위해 제공하는 기능인데 SQL의 조인 종류와는 다르다.
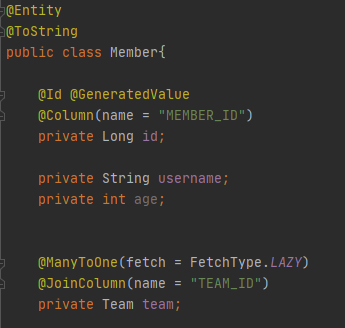
예를 들어 Member와 Team의 간의 일대다 다대일 연관관계가 되어있고,
Member와 Team은 지연 로딩이 설정되어있다.

여기서
Team ==> 팀1 팀 2
Member => 나무늘보, 나무늘보 2, 나무늘보 3
나무늘보, 나무늘보 2 => team
나무늘보 3 => team 2에 소속되어있다고 설정하고,
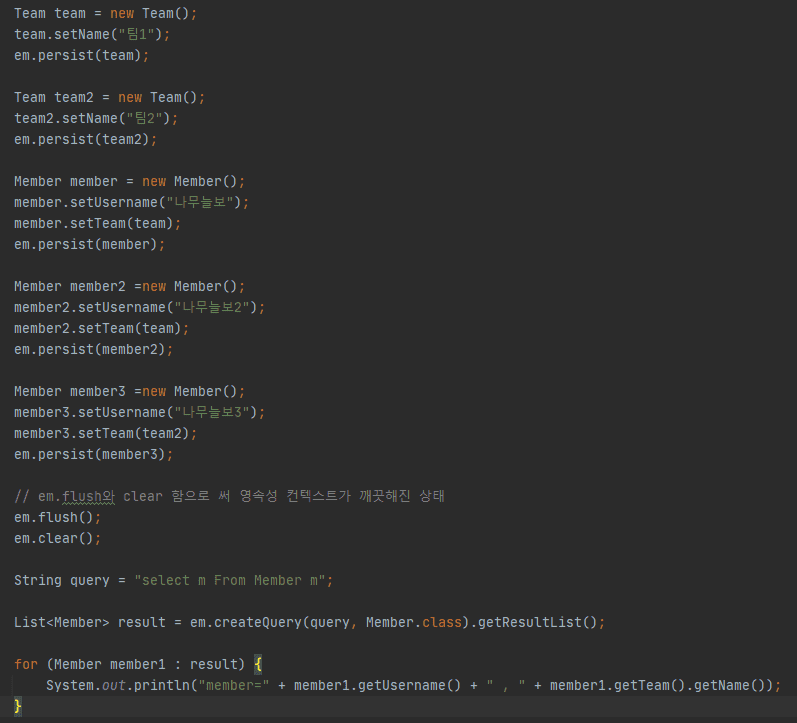
JPQL를 사용해 Member를 가져온 뒤,
for문을 사용해서 Member의 username과 관련된 team의 name을 가져온다고 한다면
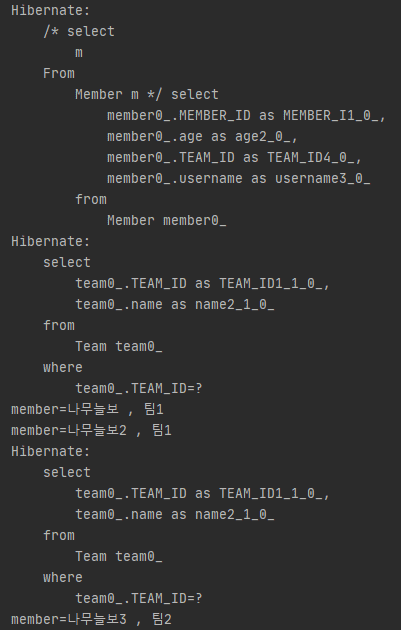
우선 select를 통해 Member를 가져오고 Team은 지연 로딩, 즉 프록시 이므로 영속성 컨텍스트로 부터 요청하여 select문을 통해 팀 1을 가져오는 것을 볼 수 있다.
나무늘보 1, 나무늘보 2는 팀 1 소속이니 한 번가 져온 팀 1은 나무늘보 2에서 팀을 가져올 때 더 이상 select문을 호출하지 않지만 나무늘보 3은 다른 팀 소속이므로 한번 더 select쿼리가 나가는 것을 볼 수 있다.
이것을 N+1문제라고 하는데
만약 서로 다른 소속의 회원이 100개라면 N+1의 '1'은 회원을 불러오기 위한 첫 번째 쿼리 한 번인데 팀을 찾기 위해서 100번이 나가는 문제이다.
이것을 해결하기 위해 fetch join이 필요한데 우선, 다 대 일 관계에서의 fetch join)

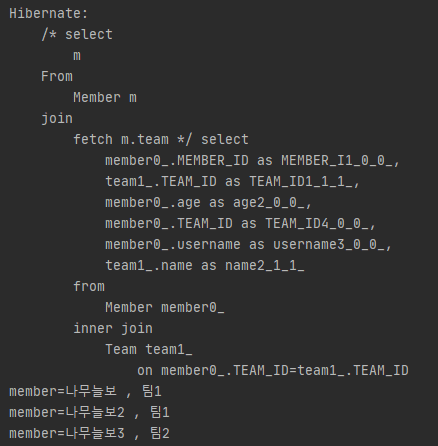
Member를 찾는 쿼리가 한번 실행할 때 Team과 join 하여 한번에 실행 결과를 찾을 수 있다.
다 대 일 관계에서의 fetch join)

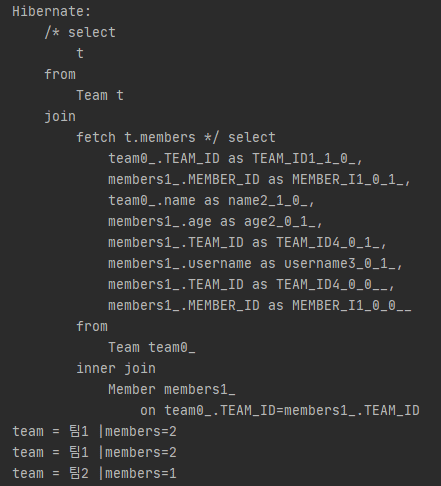
정상적으로 fetch join을 한 것 같지만
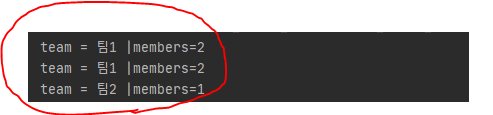
팀 1의 출력이 중복으로 된다는 것이다.
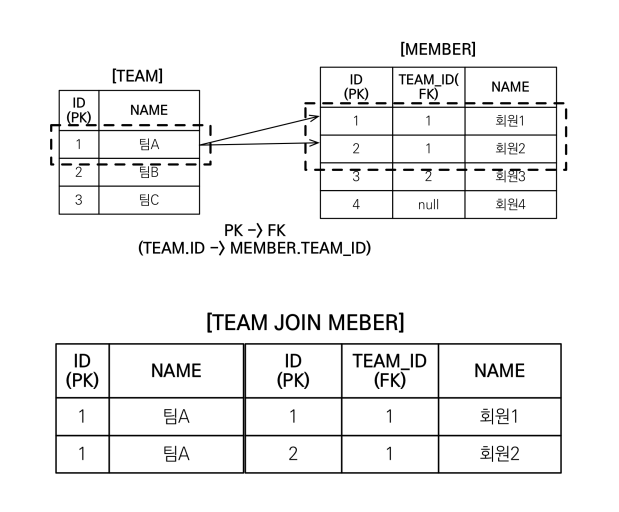
이렇게 팀 A가 회원 2개를 참조하고 join을 하면 SQL입장에서는 데이터를 뻥튀기? 할 수밖에 없기 때문에 결과가 중복으로 나오는 것이다.
이것을 해결하려면 DISTINCT를 사용하면 된다.
JPQL에서의 DISTINCT는 2가지 기능을 제공하는데
1. SQL에 DISTINCT를 추가
2. 애플리케이션에서의 엔티티 중복 제거
SQL에서도 DISTNICT를 사용하면 중복을 제거할 수 있지만,
SQL의 경우 [참고 1]의 맨 아래의 테이블처럼 모든 값이 같지 않으면 중복을 제거할 수 없기 때문에 결과적으로 중복제거를 실패한다.
하지만 JPQL의 DISTINCT의 경우

같은 식별자를 가진 엔티티를 제거해 주기 때문에 결과도 달라진다.



위의 쿼리와 같이 다 대 일의 경우 fetch join을 할 때 distinct를 사용하고 Team과 Member를 조회하면
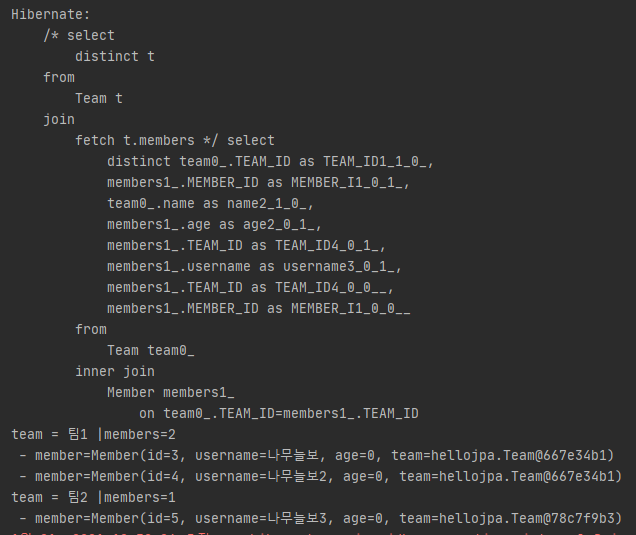
select문이 한 번만 나갈뿐더러 결과 값이 중복되지 않고 잘 나오는 것을 볼 수 있다.
'JPA' 카테고리의 다른 글
| [JPA] 쿼리 작성 법 (0) | 2021.01.21 |
|---|---|
| [JPA] 페치 조인(fetch join)의 한계 (0) | 2021.01.21 |
| [JPA] 지연 로딩과 즉시 로딩 (2) | 2021.01.09 |
| [JPA] 프록시란? (0) | 2020.12.23 |
| 상속관계 매핑 (0) | 2020.12.22 |



